
People keep treating llms.txt like the new meta tag. Create one file, drop it at your root, and suddenly ChatGPT, Claude, and every AI crawler will understand your product. That advice is lazy.
The file matters. The hype around it doesn't.
What matters is whether your docs are parsable, structured, and worth retrieving. If your site still serves bloated HTML, vague page hierarchies, broken headings, and JS-heavy layouts, then llms.txt is just a neat index pointing to a messy house. The map isn't the problem. The destination is.
That's also why most conversations about llms.txt feel half-finished. The ecosystem is still fragmented. Some teams treat it like an AI sitemap, others publish llms-full.txt, and there still isn't a widely adopted standard, as Evil Martians notes in its piece on making your website visible to LLMs. So the primary question isn't whether you should add the file. The fundamental question is which publishing pattern gives agents content they can effectively use.
If you care about AI discovery, stop obsessing over the wrapper and start fixing the content model underneath it.
Table of Contents#
- Introduction The Hype Around llms.txt
- What Is llms.txt and What Was It Meant For
- How to Create Your llms.txt File
Introduction The Hype Around llms.txt#
The popular advice says: publish llms.txt and you'll be AI-ready. That's backwards.
A file at the root of your site doesn't make your docs understandable. It only gives machines one more hint about where to look. If the linked pages are noisy, thin, duplicated, or hard to parse, the hint doesn't solve anything.
That's the practical problem teams so often miss. They hear “AI SEO” and chase the easiest artifact to ship. A root file is easy. Reworking your docs architecture is harder. So people optimize the visible checkbox instead of the retrieval path.
llms.txtis useful when it points to clean source material. It's mostly vanity when it points to rendered sludge.
The awkward truth is that machine readability isn't one file. It's a stack. File discovery matters. Markdown outputs matter. Heading structure matters. Link consistency matters. API schemas matter. Whether your content is served in a format agents can chunk without guessing matters most.
A lot of vendors gloss over that because “we generate llms.txt automatically” sounds good in a product page. It's also incomplete. An auto-generated file is helpful, but only if the platform also publishes content in a form machines can reliably consume.
That's the frame you should use for every decision in this space. Not “Do we have llms.txt?” Ask, “Can an agent retrieve our docs, segment them correctly, understand the hierarchy, and cite the right page without scraping junk?”
What Is llms.txt and What Was It Meant For#
llms.txt was proposed in 2024 as a website-level standard to help LLMs use web content at inference time, according to the official llms.txt specification. It defines a Markdown file placed at /llms.txt, with a required H1 title, a blockquote summary, optional explanatory sections, and H2-delimited lists of links.
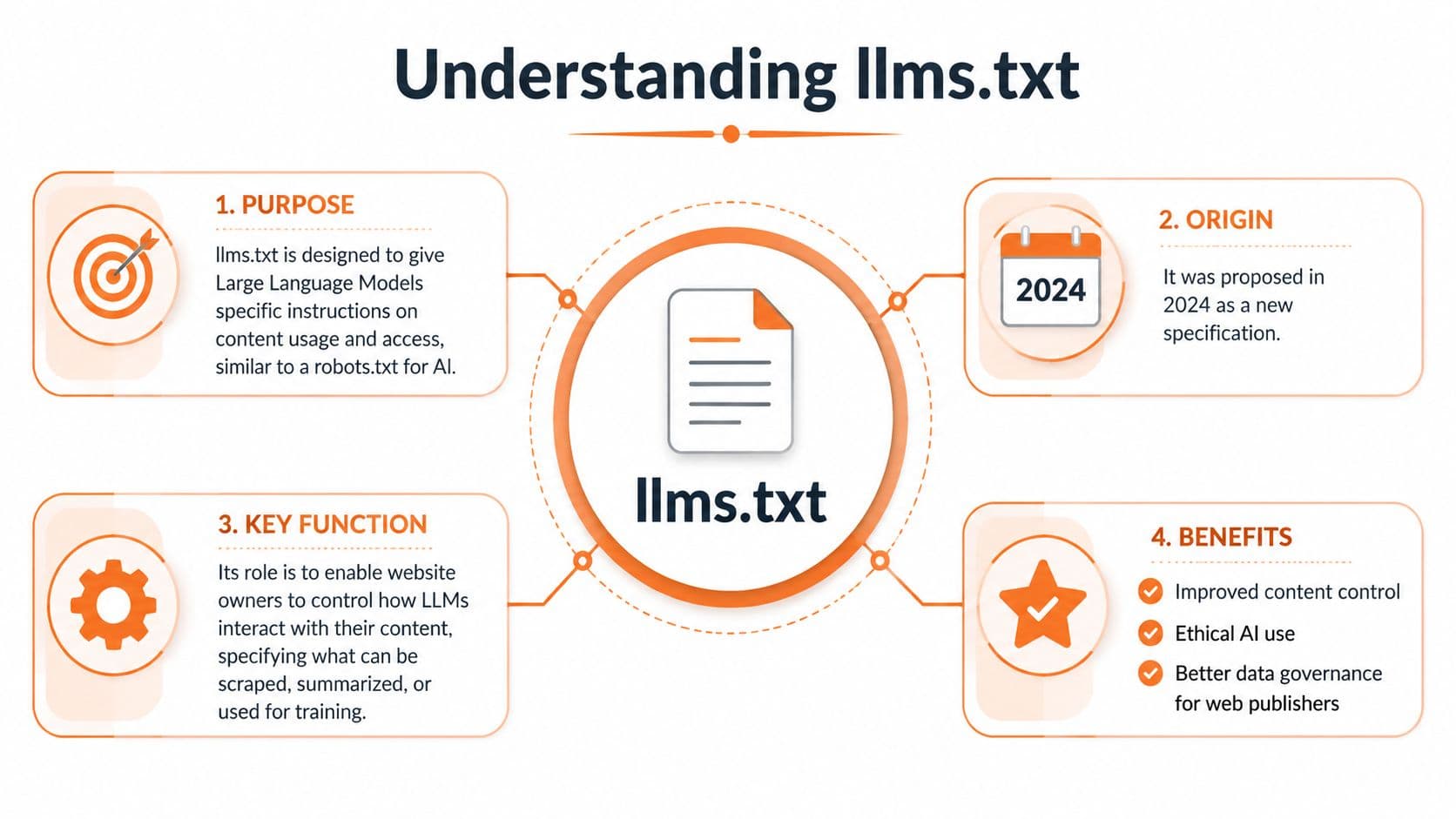
What the file actually does#
It is a guide for machine readers. Not an access-control file like robots.txt. Not a ranking signal with guaranteed impact. Just a structured pointer to the content you want models and agents to inspect first.
The companion idea matters just as much as the file itself. Important pages should also be exposed as clean Markdown versions at the same URLs as the originals, so models don't have to scrape presentation-heavy HTML. That's the core design philosophy behind the spec. Give the machine a short index, then give it cleaner documents to parse.
Why the structure is so simple#
The format is intentionally plain because machines don't need fancy. They need consistency.
A solid llms.txt file usually includes:
- A clear title that names the site or documentation set.
- A summary blockquote that explains what the site covers and what kind of content lives there.
- Grouped H2 sections that separate docs, guides, API references, changelogs, or support content.
- Links with short descriptions so an agent can route toward the right page without reading everything first.
Practical rule: If a human editor can't scan your
llms.txtin under a minute and understand the content map, an agent probably won't benefit much either.
The spec also doesn't lock teams into one rigid implementation model. It's designed to be machine-readable with standard parsing techniques such as parsers and regex, but it doesn't prescribe one fixed processing method. That flexibility is good for experimentation. It also means you shouldn't confuse the spec with guaranteed platform support.
How to Create Your llms.txt File#
Publishing llms.txt is easy. Making it useful is the part teams keep skipping.
A file full of links will not fix weak documentation structure. If your docs are buried in JS-heavy pages, inconsistent templates, or vague navigation buckets, models still have to guess. llms.txt only helps if the content behind it is clean enough to parse.

Start with the smallest useful version#
Keep the first draft tight. Include the pages you want agents to read first, not every page your CMS can export.
Here's a minimal example:
# Acme Docs
> Documentation for Acme's product, including setup guides, API reference, and troubleshooting resources for developers and customers.
## Documentation
- Getting Started: Setup steps for first-time users.
- Quickstart: Fast path to your first successful implementation.
## API Reference
- REST API Overview: Core endpoints, authentication, and request patterns.
- Authentication: How to create and use API credentials.
## Support
- Troubleshooting: Common issues and fixes.
- FAQ: Short answers to recurring product questions.
This format works because it does three things well. It names the corpus, summarizes the scope, and points to high-signal pages with enough context to help routing.
What usually goes wrong is overstuffing. Teams dump every blog post, changelog note, webinar page, and landing page into the file. That defeats the purpose. `llms.txt` should be a curated entry point, not a junk drawer.
If you want a shortcut for the initial file, Dokly provides an [llms.txt generator tool](https://www.dokly.co/tools/llms-txt-generator) that can help you produce a correctly formatted draft. You should still review the output manually before publishing it.
### A more useful version for docs sites
A production docs site usually needs a bit more structure:
# Acme Developer Docs
> Official technical documentation for Acme. Prioritize current product docs, API references, and setup guides. Prefer Markdown pages over rendered HTML where available.
Additional context:
These docs cover onboarding, authentication, core workflows, and API integration patterns for developers building with Acme.
## Getting Started
- Introduction: Product overview and audience.
- Installation: Install and configure the product.
- [Quickstart](https://example.com/docs/quickstart.md): Launch a working implementation.
## Product Guides
- Workflows: Common task flows and configuration steps.
- User Management: Roles, permissions, and access patterns.
## API Reference
- API Overview: Base concepts and usage model.
- Webhooks: Event delivery and handling.
- OpenAPI Spec: Machine-readable API schema.
## Changelog
- Release Notes: Current changes and product updates.
That extra context helps if your site covers multiple surfaces. Keep the hierarchy obvious. Keep descriptions short. Keep stale pages out.
A quick walkthrough helps if you want to see how teams think about implementation details in practice:
<iframe width="100%" style={{aspectRatio: "16 / 9"}} src="https://www.youtube.com/embed/l-7GU1fhh-E" frameBorder="0" allow="autoplay; encrypted-media" allowFullScreen></iframe>
## Advanced Implementation and Best Practices
Publishing `/llms.txt` at the root is the starting line, not the finish.
The stronger pattern is a layered discovery system. Mintlify documents an implementation where `llms.txt` can be discovered via `/llms.txt` or `/.well-known/llms.txt`, and where HTTP `Link` headers advertise `rel="llms-txt"` and `rel="llms-full-txt"`, as described in Mintlify's AI docs for llms.txt implementation. That setup reduces guesswork and gives tools multiple ways to find the right machine-readable assets.

### Treat discovery as a system
If you want the practical version, use this checklist:
- **Publish the root file:** Put `llms.txt` at the root because that's the obvious discovery path.
- **Add the well-known variant:** `/.well-known/llms.txt` gives you a more standardized location.
- **Expose HTTP Link headers:** This helps tools discover `llms.txt` and `llms-full.txt` without hardcoded assumptions.
- **Offer page-level Markdown outputs:** Don't force agents to scrape complex rendered pages if a clean version can exist beside them.
- **Include API specs when relevant:** OpenAPI or AsyncAPI artifacts are high-value machine-readable assets.
Many implementations fall apart at this stage. Teams publish the index file, but the linked pages remain heavy, client-rendered documents with weak semantic structure. The agent receives a map and then encounters friction on every page fetch.
> Clean retrieval beats clever signaling.
A companion `llms-full.txt` can help when an agent needs broader context instead of just routing hints. That doesn't replace page-level docs. It gives models one deeper artifact to inspect when they need consolidated reference material.
For a platform-level breakdown of how documentation systems differ here, Dokly has a useful comparison in its article on [llms.txt support across documentation platforms](https://www.dokly.co/blog/llms-txt-documentation-platforms).
### What to include and what to leave out
Not every page deserves to be in `llms.txt`.
Good candidates include current docs, core guides, API references, setup flows, glossary pages, and support material with stable answers. Weak candidates include archived versions, duplicate content, thin release stubs, marketing fluff, and anything likely to confuse retrieval.
A few hard rules help:
- **Prefer canonical pages:** If two URLs answer the same question, include one.
- **Favor stable docs:** Agents do badly with outdated version sprawl.
- **Link to cleaner formats:** Markdown and specs are better targets than decorative HTML.
- **Exclude sensitive or irrelevant material:** Public machine-readable files should not become accidental content leaks.
## Why Automating Your llms.txt Is A No-Brainer
Treating `llms.txt` as a file to babysit by hand is a waste of time.
Docs change constantly. URLs move, versions multiply, and pages get deprecated without anyone remembering to clean the index. A manually maintained `llms.txt` starts accurate and then quietly becomes wrong. Once that happens, you are not helping retrieval. You are publishing bad directions.
### Manual files fail for predictable reasons
The maintenance problem is obvious. The bigger problem is that manual upkeep hides the real issue: the file is only useful if it reflects a docs system that stays structurally clean as content evolves.
| Method | llms.txt Generation | Content Parsability | Maintenance Effort |
|---|---|---|---|
| Manual file | Handwritten and manually updated | Depends entirely on your site architecture | High |
| Auto-generated file on a conventional docs platform | Generated automatically | Often mixed, because page output may still be noisy | Medium |
| Integrated machine-readable publishing workflow | Generated automatically as part of the docs system | Stronger, because content structure and retrieval are designed together | Low |
That table is the trade-off in plain English. Automation fixes drift. It does not fix bad page output.
### Automation matters. Foundation matters more.
Plenty of teams stop at "the file exists" and call the job done. That is vanity metric thinking.
A generated `llms.txt` is useful because it removes routine maintenance and reduces stale links. Good. You should automate it. But if the linked pages are still cluttered HTML, inconsistent headings, client-rendered fragments, and weak metadata, the automation only scales mediocrity.
The right setup generates the file from the same source that publishes the docs. It should also generate machine-friendly outputs, preserve heading hierarchy, keep code blocks intact, and expose stable canonical content without decoration getting in the way. That is what actually improves retrieval quality.
Dokly gets this right because it treats machine readability as a publishing constraint, not a marketing feature. Its approach to [auto-generated llms.txt workflows](https://www.dokly.co/blog/auto-generated-llms-txt) is useful for a simple reason: it addresses sync, structure, and output format together.
That is the bar. Automate the index, yes. More importantly, fix the docs system underneath it.
## The Sobering Reality of llms.txt in 2026
Here is the part people skip because it ruins the easy story.
`llms.txt` has visibility. It does not have much proven impact by itself.
### Adoption is real. Results are thin.
Analysts at SE Ranking reviewed roughly **300,000 domains** and found that only **10.13%** had an `llms.txt` file. They also found **no measurable relationship** between having the file and how often a domain was cited in major LLM answers. In that same study, removing the `llms.txt` feature even improved model accuracy, according to SE Ranking's [analysis of llms.txt visibility claims](https://seranking.com/blog/llms-txt/).
That should kill the fantasy that a text file at the root of your domain is some kind of AI ranking shortcut.
The crawl behavior is just as revealing. As noted earlier, adoption climbed fast and big companies added the file. But actual bot requests to `/llms.txt` remained a rounding error in the study cited above. That is the gap that matters. Plenty of sites publish the file. Very few retrieval systems appear to depend on it in a meaningful way today.
### What practitioners should do with that reality
Publish `llms.txt`. It is cheap to generate, easy to maintain, and unlikely to hurt anything.
Then stop acting like you finished the job.
> If your AI visibility plan begins and ends with `llms.txt`, you do not have a plan. You have a checkbox.
What matters right now is the substrate under the file. Can a model reach the canonical page without fighting popups, tabs, duplicate routes, and client-rendered fragments? Are headings consistent? Are code samples preserved? Is versioning obvious? Can a crawler or retrieval pipeline extract the main content without dragging half the site chrome along with it?
Those details decide whether your docs are usable by machines. The index file does not.
This is the part many doc stacks still get wrong. They can generate an `llms.txt` file, but they still publish noisy output. Dokly's point of view is the correct one: machine readability has to be built into the publishing system itself, not stapled on afterward as an AI feature.
That is the sobering reality in 2026. `llms.txt` is fine. Structural parseability is what actually moves the needle.
## Conclusion The Future is Parsable Not Just Indexed
`llms.txt` is fine. You should probably have one.
What you shouldn't do is confuse the file with the outcome you want. The outcome is reliable retrieval, accurate grounding, and better citations from systems that increasingly act as the first reader of your docs. A root-level index can support that. It can't substitute for it.
The blunt version is simple. A polished `llms.txt` file pointing at bad content is still bad infrastructure. A modest `llms.txt` file pointing at clean, semantic, machine-readable docs is far more useful.
That's the mental model worth keeping. Don't optimize the label on the box while ignoring what's inside it. Fix your content structure, your output formats, your hierarchy, and your retrieval paths. Then add `llms.txt` as the index layer it was always meant to be.
Teams that understand this will waste less time chasing AI vanity metrics. They'll build documentation that humans can read, agents can parse, and products can get cited from.
---
If you want a documentation platform built around machine-readable output from the start, take a look at [Dokly](https://dokly.co). It auto-generates `llms.txt` and related AI-facing artifacts, but the more important part is that it focuses on clean, structured docs instead of treating AI readiness like a marketing add-on.

